
Regular expressions: those seemingly non-sensical strings of characters that seem to magically take an input string and determine whether it matches a pattern that you have some how supposedly described with the previously mentioned non-sensical string of characters.
Being a self admitted perl lover, I have always been mystified by the power of regular expressions: the seemingly black magic functionality used by many, but seemingly only mastered by the real grey beards. At the same time you can’t deny their every-day utility. I regularly make use of regular expressions in Java to do DTO level field validation in springboot projects and various scripts at work.
So what gives, how do these seemingly magical line noise do what they do? It turns out that the concept isn’t actually all that difficult to understand once you sit down and decide to wrap your head around it. There are many different algorithms and approaches to solving this problem. Some are easier to implement then others, some are easier to understand than others, and most importantly: some are a whole HECK of a lot faster than others.
A lot of what drives the various approaches to making regular expressions work is recognizing their similarity to mathematical expressions: They have syntax, operators and precedence. They require parsing, and are then interpreted, or translated (compiled) in order for them to run some form of state machine, in this particular case called a regular expression engine. If you are not familiar with evaluating algebraic expressions, I have covered it in a previous post on stack machines and compilers.
Regular expression engines can be found in almost every modern programming language, and in various libraries for other languages that don’t have them natively. In this post I’m going to talk about a couple of different approaches to implementing a regular expression engine, as well as walk through implementing one of the easier to understand approaches.
A Brief History of Regular Expressions
The entire history of regular expressions(Reg ex’s) can be traced back to the work of theoretical computer scientist Stephen Cole Kleene in the early 1950’s. His work resulted in what has come to be known as Kleene’s Theorem which outlines the relationship between regular expressions, language, and finite automatons. More precisely, it states that for every regular expression their is a finite automaton capable of consuming any valid regular expression, and conversely, for every finite automaton there is a valid regular expression capable of describing it.
Some of the earliest work was based on Deterministic Finite Automata(DFA) however it was quickly realized that Non Deterministic Finite Automata(NFA) were more aptly suited(albeit slower) for the task. Not to mention being more computationally powerful in general.
Regular expressions gained widespread use in computer science thanks to the influential paper “Programming Techniques: Regular Expressions in Search” By Ken Thompson (yes, that Ken Thompson) in 1968. It outlines what’s come to be known as ‘Thompsons Construction’ algorithm, from which many modern implementations derive. It is also this algorithm that was used to implement the original Unix grep command. For those who may not be aware, grep stands for ‘Global search for Regular Expressions and Print matching.’
The introduction of the awk programming language by Aho, Weinberg, and Kernigan at bell labs helped to promote the incorporation of regular expressions into programming languages. This influential work gave rise to what has become hands down regular expressions greatest success story: Perl.
Practically from its inception, the Perl programming language made judicious use of regular expressions, introducing them to an entire generation of developers who powered the early internet, proving their utility and carrying them forward as a mandatory component of every modern programming language – often with syntax similar to, or directly compatible with, the Perl implementation.
More recent developments have given rise to alternative approaches to the traditional top down parsing recursive backtracking approach, such as the virtual machine interpreters employed by Rob Pike in his RE and RE2. These strive to avoid some of the problems that can arise from various bad inputs to the backtracking variety.
Ok, enough history, Let’s code!
Non-Deterministic Finite Automata
NFA’s are, in short, a high level abstraction for a certain (non-general) model of computation. They are used to describe a theoretical state “machine” – a type of mathematical object – which we implement via further abstractions. What I’m trying to say is, an NFA is an idea. The actual implementation is determined by how the individual programmer decides to implement the abstractions in order to devise a concrete implementation. Needless to say, there are a lot of different ways to go about it. Some implement a byte-code-interpreter-like virtual machine[5], other implementations very similar to a backtracking recursive descent parser[4].
Let’s take a moment to formally define the characteristics of Non-deterministic Finite Automata:
- For a regular expression of length M, an NFA has one state for each character in the pattern. The starting state is always 0, the accepting state is always M+1;
- Match states can only have edges pointing to the next character in the pattern.
- Transition states can have edges pointing to any other state in the graph, and must have at least one outgoing edge.
- No state can have more than one Match state, though they can have multiple transition states.
When an we build an NFA from a regular expression pattern, it is said to have been ‘constructed’. Using the constructed NFA to recognize the pattern described by the regular expression in a piece of text provided as input is called ‘Simulating the NFA’.
Operators
Practically any Regular Expressions can be composed from four fundamental operations with differing ordering precedence, represented by the following operators in regular expression syntax[2]:
- Concatenation – concatenation has no explicit operator, instead it is simply represented by adjacent values, the regular expressions “AB” means, an ‘A’, followed by a ‘B’, a 2 character string formed by concatenating the letters A and B.
- OR – this operator gives us the power of choice, it is represented by the ‘|’ symbol, following the example from above, “A|B” means an ‘A’ or a ‘B’, a 1 character string comprised of either the letter ‘A’ or the letter ‘B’.
- Closure – represented by the “Kleene Star” ‘*’, named for Stephen Kleene. Closures are used to represent 0 or more occurrences of the preceding letter. So “AB*” means, a single ‘A’ with no ‘B’, an ‘A’ with 1, or any higher number of repeating ‘B’s.
- Parentheses – Parentheses are used to override precedence to express things such as “(A|C)|(B|D)”, which matches “AC” “AD” “BC” and “BD”.
Each one of these operations can be used to construct small individual NFA’s which can then strung together and combined resulting in the complete, more powerful construct, capable of recognizing patterns in text[3].
Various other “shortcuts” can be added to increase expressiveness, such as set descriptors, closure shortcuts, and escape sequences, but we can do pretty much any of these things using just these four basic operations.
Our first step in implementing regular expression engine is to build our state machine – the nondeterministic finite automaton.
State Changes
State machines such as our NFA keep track of their internal state, and depending on some input or rule, change this internal state accordingly. These state changes are called transitions, and each transition is represented by an edge in a directed graph. NFA’s for regular expressions have two types of transitions:
- Match Transitions – This type of transition occurs when the character being examined is a valid match to a character in the regular expression and in the languages alphabet. When a Match transition occurs, a character of the string being examined is consumed, meaning we move forward a place.
- Epsilon Transitions – These are transitions which take place without consuming a character, like what happens when we encounter the closure operator or left parentheses.
To use an NFA for validating a string, we only need the Digraph formed from the epsilon transitions present.
Constructing NFAs from Regular Expressions
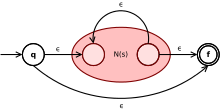
![Non-deterministic Finite Automata [12] | Download Scientific Diagram](https://www.researchgate.net/publication/228979675/figure/fig2/AS:300865580748807@1448743352922/Non-deterministic-Finite-Automata-12.png)
The key insight that drives Sedgewick’s implementation, which I will cover below, was his observation that evaluating regular expressions can be reduced to a graph reachability problem. How is this so? Well, as pictured above, NFA’s are generally visualized as directed graph, with each character in the regular expression serving as a vertex, and each state transition is represented as an edge between the vertex being examined, and the next possible state (if one exists).
In many implementations this graph is modeled as linked lists of constructs, with each node in the linked list representing one of the possible steps as shown above[3]. A good example of this is approach discussed by Russ Cox in his paper “Regular Expressions can be fast and simple”[5] which is linked below.
In the 4th edition of “Algorithms”[2] Sedgewick & Wayne took a much different approach to representing and simulating the NFA. Instead of creating each construct explicitly, they model the individual machines by creating the appropriate edges in an adjacency list representation of a directed graph. In this way, it is possible to simulate the NFA by performing multiple depth first searches from each next state to gather the next possible states, and repeating until a match is found, or all states have been exhausted, instead of traversing a list of object as is done in [3] and [5]. This higher level of abstraction, combined with a clever use of data structures and a different way of looking at a familiar problem have resulted in an implementation that is very straight forward to understand.
I’ve translated the original Java code presented in “Algorithms”[2] to C++. Where possible I’ve used STL containers adapted to match the API and naming convention used in the book.
The Bag ADT was easily mimicked with std::vector, requiring only the renaming of push_back() to add(). I return a reference to the object from add to facilitate chaining multiple calls to add, this is optional.
template <class T>
struct Bag : public vector<T> {
Bag& add(T info) {
vector<T>::push_back(info);
return *this;
}
};
Equally trivial was a modification to the behavior of std::stack. pop() was overridden to return the value being popped from the stack instead of throwing it away.
template <class T>
struct Stack : public stack<T> {
T pop() {
T ret = stack<T>::top();
stack<T>::pop();
return ret;
}
};
The Digraph ADT is an adjacency list representation of a directed graph. It supports the ability to add a one way edge connecting two vertices, return a list of the neighboring vertices of a given vertex, and return the number of vertices in the graph. One thing to keep in mind when designing the Digraph data structure is what will be used as vertex labels. The following is the result of constructing the NFA, it is the adjacency list of the epsilon transition graph for the regular expression “((A*B|AC)D)”:
0('('):
--> 1('(')
1('('):
--> 2('A')
--> 6('A')
2('A'):
--> 3('*')
3('*'):
--> 2('A')
--> 4('B')
4('B'):
5('|'):
--> 8(')')
6('A'):
7('C'):
8(')'):
--> 9('D')
9('D'):
10(')'):
--> ('$')
11('$'): (ACCEPT)
0 1 2 3 4 5 6 7 8 9 10 11
( ( A * B | A C ) D ) $(ACCEPT)
A regular expression may have repeated characters, but each instance of these characters are their own unique vertex. To account for this, the index of the character is used to represent the vertex instead of the character its self. Doing otherwise would risk resulting in the adjacency lists being inaccurate, the DFS phase visiting the wrong vertices, or any number of issues depending on what structure is used to actually implement the adjacency list. In our case, a simple array of Bag’s fits the use case perfectly.
class Digraph {
private:
int _v;
Bag<int>* adjlist;
public:
Digraph(int numv = 5) {
adjlist = new Bag<int>[numv];
_v = numv;
}
Digraph(const Digraph& o) {
_v = o._v;
adjlist = new Bag<int>[o._v];
for (int i = 0; i < o.V(); i++) {
if (!o.adjlist[i].empty()) {
for (int u : o.adjlist[i]) {
addEdge(i, u);
}
}
}
}
~Digraph() {
if (adjlist != nullptr)
delete [] adjlist;
}
void addEdge(int v, int w) {
adjlist[v].add(w);
}
Bag<int>& adj(int v) {
return adjlist[v];
}
int V() const {
return _v;
}
Digraph operator=(const Digraph& o) {
_v = o._v;
adjlist = new Bag<int>[o._v];
for (int i = 0; i < o.V(); i++) {
if (!o.adjlist[i].empty()) {
for (int u : o.adjlist[i]) {
addEdge(i, u);
}
}
}
return *this;
}
};
Our last auxiliary component is the search function. Theoretically any uniformed search algorithm that can be used for reachability problems, such as breadth first search will suffice. For our use case, the simplest of the bunch will do: a recursive pre-order depth first search. This makes sense because the matching phase of the algorithm is essentially the same as Tarjan’s Connected Components algorithm run through several times.
Our DFS class has one crucial addition not usually present that pretty much makes this whole approach possible. It caches the visited list and provides the method marked() which allows us to check which vertices were visited both during a traversal and after it has completed.
class DirectedDFS {
private:
bool* seen;
int numv;
void search(Digraph& G, int v) {
seen[v] = true;
for (int u : G.adj(v))
if (!seen[u])
search(G, u);
}
void initseen(size_t size) {
numv = size;
seen = new bool[size];
for (int i = 0; i < size; i++)
seen[i] = false;
}
public:
DirectedDFS(Digraph& G, int v) {
initseen(G.V());
search(G, v);
}
DirectedDFS(Digraph& G, Bag<int>& src) {
initseen(G.V());
for (int v : src)
if (!seen[v])
search(G, v);
}
DirectedDFS(const DirectedDFS& o) {
if (o.numv > 0) {
numv = o.numv;
seen = new bool[numv];
for (int i = 0; i < numv; i++)
seen[i] = o.seen[i];
}
}
~DirectedDFS() {
if (seen != nullptr)
delete [] seen;
}
bool marked(int v) {
return seen[v];
}
DirectedDFS operator=(const DirectedDFS& o) {
if (o.numv > 0) {
numv = o.numv;
seen = new bool[numv];
for (int i = 0; i < numv; i++)
seen[i] = o.seen[i];
}
return *this;
}
};
Ok, so now we have all of our supporting data structures, it’s time to construct the NFA. Our NFA class will have a private instance of Digraph, an internal copy of the regular expression it is representing, and a count of the number of states.
class NFA {
private:
Digraph G;
string re;
int m;
void buildEpsilonDigraph();
public:
NFA(string regex);
bool match(string text);
};
Each part on its own is a straight forward process, and what happens when you combine them has strong connections to the entire theory of computation and especially programming languages. So lets get into to it.
The constructor takes as input the regular expression to be simulated. It the assigns a local copy of the regex stored in ‘re’, the number of characters in re is the number of possible states, and is stored in m. G is our directed graph, and is initialized to have m+1 vertices, with vertex m+1 being our virtual match state. Once these parameters are initialized, we call the buildEpsilonGraph() method, I believe you can surmise the reason. The showNFA() method is not required, it just prints out a visual representation of the graph created.
NFA(string regexp) {
re = regexp;
m = re.length();
G = Digraph(m+1);
buildEpsilonGraph();
showNFA();
}
buildEpsilonGraph() works as a combination parser/validator/graph constructor, and if you have read my previous article on evaluating algebraic expressions, should seem some what familiar. Indeed, we once again find our selves maintaining a stack, and performing actions upon encountering parentheses. These similarities are not a coincidence, and at the risk of repeating myself help to show the relation of regular expressions to the very foundations of computing.
Any state transition that is an edge leaving from a parentheses is an epsilon transition. Any edge leaving from a member of the alphabet, or a non parentheses operator is a match transition.
A stack is initialized to hold the operators encountered as we process the regular expression by iterating over its string representation. At the beginning of each iteration, we make a copy of the current left position in the string and store it in a value, `lp`. When we encounter a left parentheses or a logical-or symbol (‘|’) we push it’s index to the ops stack.
void buildEpsilonGraph() {
Stack<int> ops;
for (int i = 0; i < m; i++) {
int lp = i;
if (re[i] == '(' || re[i] == '|')
ops.push(i);
When we encounter a closing (right) parentheses, we pop the most recent operator from the stack and store it in a variable ‘r’, if the character at index ‘r’ is the `or` symbol, we pop the top value of the ops stack into lp and create the edge representing the or operation. Otherwise, reset the value of lp to the current position in the regular expression string.
else if (re[i] == ')') {
int ro = ops.pop();
if (re[ro] == '|') {
lp = ops.pop();
G.addEdge(lp, ro+1);
G.addEdge(ro, i);
} else lp = i;
}
Next, we implement the closure operator which necessitates the use of a ‘lookahead’, which is a fancy way of saying we look at one position past the current position (so long as were not at the last position) to determine what to do.
if (i < m - 1 && re[i+1] == '*') {
G.addEdge(lp, i+1);
G.addEdge(i+1, lp);
}
All that’s left is to construct the edges that result for encountering parentheses, or for when the closure operator is the current character (not the look ahead).
If, when were done iterating over the string, there are still operators on the stack, then something didn’t work and you should first check your regex syntax, and then your code (Note: if this occurs, then you are now essentially debugging two programming languages. This is one of the classic arguments against the use of regular expressions: “I had a problem I thought I could solve with regular expressions. Now I have two problems.”)
if (re[i] == '(' || re[i] == '*' || re[i] == ')')
G.addEdge(i, i+1);
}
if (!ops.empty()) {
cout<<"Something went wrong."<<endl;
}
}
void showNFA() {
for (int i = 0; i < G.V(); i++) {
if (i < re.size()) {
cout<<i<<"("<<re[i]<<"): "<<endl;
for (int u : G.adj(i)) {
if (u < re.size()) {
cout<<" --> "<<u<<"("<<re[u]<<") "<<endl;
}
}
} else {
cout<<"$ (Match)."<<endl;
}
}
}
I’ve included the code for showNFA(), I believe its implementation speaks for its self, so I’ll save myself the trouble of explaining.
If your regular expression compiled (something about that just sounds cool) with no problems, then it’s time to write the recognizer method. It works on a simple, elegant application of depth first search.
The matcher function takes as input the text which we are checking to see if the compiled regular expression recognizes. We begin by performing a depth first search from the first possible state, and gather all the reachable states into a set. As you will see, this process is central to the algorithm.
bool recognizes(string text) {
DFS dfs(G, 0);
Bag<int> pc;
for (int v = 0; v < G.V(); v++)
if (dfs.marked(v))
pc.add(v);
This string is then iterated over one character a time. At each iteration, we examine the states that were reached from the current state, and create a set of the next possible states:
for (int i = 0; i < text.length(); i++) {
Bag<int> next;
for (int v : pc)
if (v < m)
if (re[v] == text[i] || re[v] == '.')
next.add(v+1);
We now re run the dfs, this time using the gathered ‘next’ states. After the dfs has completed, we repeat the initial gathering of reached states, if no states were reached we can exit as it cant possibly match.
pc.clear();
dfs = DFS(G, states);
for (int v = 0; v < G.V(); v++)
if (dfs.marked(v))
pc.add(v);
if (pc.empty())
return false;
}
for (int v : pc)
if (v == m)
return true;
return false;
}
Once we have consumed the entire string, it is time to check the final set of reached states: if we reached the match state, then our NFA recognizes the string, otherwise it has not (obviously).
And that’s really all that is required to implement a limited, but fully capable regular expressions engine. But it doesn’t need to stay limited, we can implement a full set of features to give our regular expressions engine power approaching that of a system level grep or any other regular expression engine. Though admittedly some features, like back references are not the easiest construct to implement this way however.
As an example of how to extend the syntax our regular expression engine, lets implement a second closure operator. Our current closure operator will match any number of the previous character, including none. Adding an operator for matching a character that occurs at least once is generally useful, that operator is usually represented as ‘+’, and all thats required is the following change to the graph building function:
if (i < m - 1 && (re[i+1] == '*')) {
/* ..... */
/* same as above */
if (i < m-1 && (re[i+1] == '+'))
G.addEdge(i+1, lp);
if (re[i] == '(' || re[i] == '*' || re[i] == '+' || re[i] == ')')
G.addEdge(i, i+1);
}
/*same as above */
Further Reading
The following resources were utilized while researching this topic:
- Thompson, Ken “Programming Techniques: Regular Expressions in Search”, Communications of the ACM, Volume 11, Issue 6, June 1968.
- Sedgewick, Robert, Wayne, Kevin “Algorithms”, 4th edition, Addison Wesley 2008, Chapter 5, Section 4 “Regular Expressions”
- Aho, Sethi, & Ullman “Compilers Principles, Techniques, and Tools”, Addison-Wesley 1988, Bell Telephone Laboratories 1986. Chapter 3 “Lexical Analysis”, Section 6 “Finite Automata” and Section 7 “From a Regular Expression to an NFA”
- Kernighan, Brian “Beautiful Code”, O’Reilly 2007, Chapter 1 “A Regular Expression Matcher”
- Cox, Russ “Implementing Regular Expressions”, https://swtch.com/~rsc/regexp/